Inside the Black Box: Unveiling the Secrets of Database Internals
Discover Database Secrets: Disk Storage and B-Trees Explained with Rust

4+ years of experience building scalable backend systems using Node.js, Laravel, and Go. Moving towards Solution Architecture with strong foundations in distributed systems and cloud.
Passionate about system design, databases, protocols, and high-performance services.
Laravel Stream-Pulse Laravel package for Event-Driven Architecture (EDA) using Redis Streams.
Enables scalable event publishing & consuming directly inside Laravel. Ideal for real-time apps and microservice event workflows. GoQueue Lightweight, production-ready job queue in Go with multiple backends (Redis, SQLite, SQS).
Supports retries, dead-letter queues, and graceful shutdown. Benchmarked for high-throughput event processing.
Introduction
Databases are the backbone of modern software systems, enabling efficient data storage, retrieval, and management. But have you ever wondered how they work under the hood? What happens when you execute a query? How is your data stored on disk, retrieved efficiently, and maintained reliably even in the face of failures?
This article will explore the core mechanisms that make databases tick. From understanding how data is stored and retrieved using disk-based storage and the B-tree data structure to unraveling the roles of parsers and network layers in processing your queries, we’ll cover the essential components of database internals.
I have provided a hands-on example in Rust to showcase a simple yet functional database implementation. Whether you're a developer, a student, or a curious tech enthusiast, this guide will offer valuable insights into the magic behind the databases we rely on daily.
Let’s dive in!
Storage devices
To understand how databases store the data. We need to go back to the history of computers & How computers can handle the data. We all know computers can only understand 0 & 1’s. To dive deep into bit & bytes read this article before moving ahead Bits & Bytes.
Types of storage devices
Primary storage
Primary storage is the means of containing primary memory (or main memory), which is the computer’s working memory and major operational component. The primary memory is also called “main storage” or “internal memory.” It holds relatively concise amounts of data, which the computer can access as it functions.
Secondary storage
External memory is also known as secondary memory and involves secondary storage devices that can store data in a persistent and ongoing manner. These data storage devices can safeguard long-term data.
In simple terms
Imagine your desk (primary storage) and a filing cabinet (secondary storage). You keep the documents you're actively working on your desk for quick access. When you're done with them, you file them away in the filing cabinet for later use.

As we want to store a data for long time. We need a secondary storage device it can be anything [HDD or SSD]. In this article, we are going to take HDD Hard disk drive as our storage device. so, it will be very easy to understand a few concepts down the line.
Autonomy of HDD
The first commercial HDD shipped in 1956. HDDs rely on spinning magnetic disks, or platters, to store and retrieve data, reading and writing to these platters with mechanical arms. The speed at which the data can be accessed depends on the rotation speed of the platters.
An HDD stores digital data in magnetic material on rigid rotating disks. Information is written to and recovered from the disk by movable read-and-write units, called heads. These devices store data in binary form (0s and 1s), organized into addressable units like blocks or sectors.
The working principle is as simple as it stores 0 & 1 on disk. We can read that back later as many times as we want.

As we can see the HDD has moving mechanical parts that have limitations & comparatively slow if we read data from different sectors & tracks of the Hard disk drive.
How do text files store data?
A text file stores data as a sequence of characters, where each character is represented by a numerical code. These codes are typically based on character encoding standards like ASCII or UTF-8. In ASCII, each character is represented by a 7-bit binary number (ranging from 0 to 127), while UTF-8 uses variable-length encoding to support a much wider range of characters, including those from different languages and symbols.
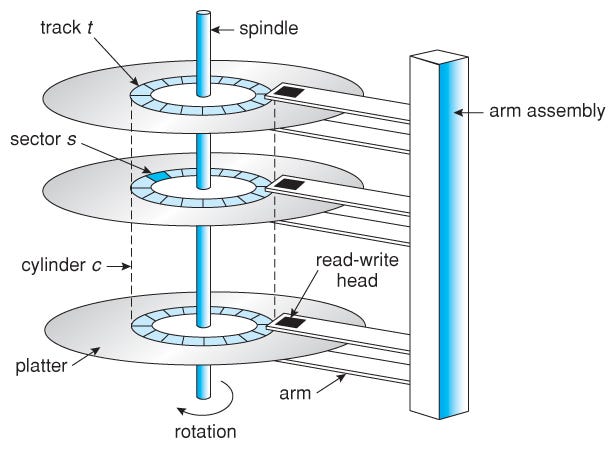
Files are managed by the file system on the operating system. Each file is saved in “unused” sectors and can be read later using its known size and position.
How do we know which sectors are occupied and which are unoccupied? What is the location of the file, position, and name? This is precisely what the file system is in charge of. A file system is a structured representation of data and a set of metadata describing this data. It is applied to the storage during the format operation. It controls how data is stored and retrieved.
Data stored in a storage medium without a file system would be one huge body of data with no way of knowing where one piece of data ends and the next begins.
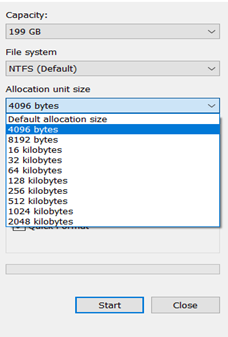
In the above figure, the allocation unit size is selected as 4096 bytes during the formatting of a hard disk. I have selected 4096 bytes for the cluster i.e. HDD used 8 sectors to form 1 cluster. The allocation size unit is the smallest bit of data that a drive can store i.e. in 1 cluster, 4KB of data is stored. To store 8 KB data, HDD allocates 2 clusters. If a file is smaller than 4096 bytes, it will still take up the entire cluster. So, If you have lots of small files, then it’s a good idea to keep the allocation size small so your hard drive space won’t be wasted. In terms of space efficiency, smaller allocation unit sizes perform better.
Movement of the magnetic head
The platter spins at thousands of revolutions per minute, allowing the magnetic head to read and write data to a specific place on the disk. The slider has an aerodynamic design that enables the head to float above the platter when it is spinning.

When the hard disk is not working, the platter is stationary and the magnetic head is close to the spindle contact. It is the surface with the smallest linear velocity, a special area that does not store any data known as the start-stop zone/landing zone, or parking zone.
Writing the data
When the computer wants to write new information, it takes a look at the file system to find some free sectors. Then the disk control starts to locate the sector with the help of the sector header. Then the disk controller moves the magnetic head component to the corresponding cylinder, gates the magnetic head, and waits for the required sector to pass under the magnetic head. When the disk controller finds the header of the sector, it decides whether to switch the write circuit or read the data and the tail record according to whether its task is to write the sector or read the sector.
Then for writing, the HDD’s logic board sends small electrical pulses to the head. When current is allowed to flow through the head, the magnetic field is induced in it which polarizes the portion of the disk that passes under the head.
Reading the data
When data needs to be read from the disk, the system sends the data logical address to the disk, and the disk control circuit converts it into a physical address according to the addressing logic, determining which track and sector the data must be read from.
Firstly, the cylinder must be found i.e. the head needs to move to align with the corresponding track. This process is called seek, and the time spent is called seek time.
Then wait for the target sector to rotate under the head, the time spent in this process is called spin time.
Then the data transfer starts i.e. data transfer time.
Order of Reading and writing data
Data reading/writing is performed on the cylinder. When the magnetic head reads/ writes data, the operation begins with the “0” head in the same cylinder and then proceeds to the various platter surfaces of the same cylinder. After all the magnetic heads on the same cylinder have been read/written, the magnetic head will move to the next cylinder, because the selection of the magnetic head only needs to be switched electronically, and the selection of the cylinder must be switched mechanically. Data reading/writing starts from the top to the bottom then from outside to inside.

Understanding Fragmentation
It is one the most important factor which determines the reading/ writing speed of a hard disk. Let’s assume we have taken a new hard disk of each sector of size 512 bytes and set our allocation unit size (cluster) to 4096 bytes i.e. 8 sectors are combined to form 1 cluster. The size of 1 cluster is 4096 bytes i.e. 4 KB. Now we are storing five files naming A, B, C, D, and E of size 4 KB each continuously. There is free space after E.

Now, if we delete file D, 4KB of free space is created and the disk becomes fragmented. Now a file naming F of size 8KB needs to store in a disk then 1st 4 KB size of F is stored in place of empty space of B and the remaining file is stored in the free space next to E. Since the contiguous cluster is not available, the data written is fragmented.

This is called the fragmentation of files. If we need to read file A the head can read it at once but if the head needs to read file F then it goanna take a few milliseconds more.
Watch the video below for better understanding on hard disk fragmentation problem.
High level Architecture
I hope now you have the understanding of how a hard disk works & tittle bit of knowledge on operating system. Which helps you to understand all the below sections of the article.
Let start dive into a high level Architecture of our database. Am using a SQLite for simplicity. It was a best database to start with as beginner.
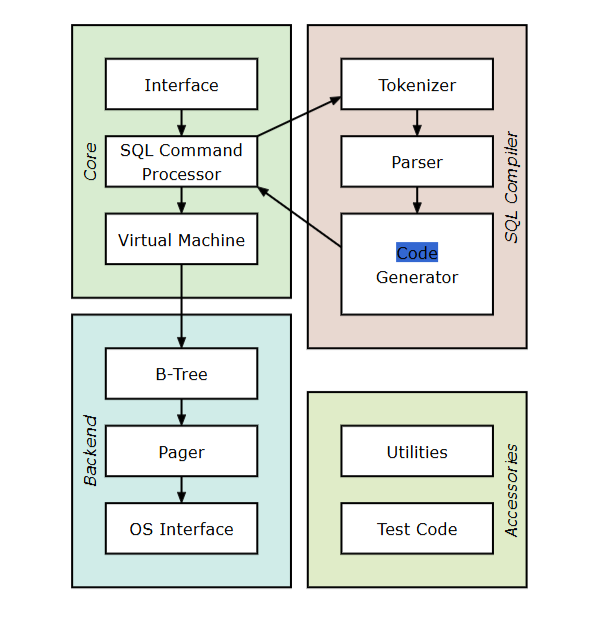
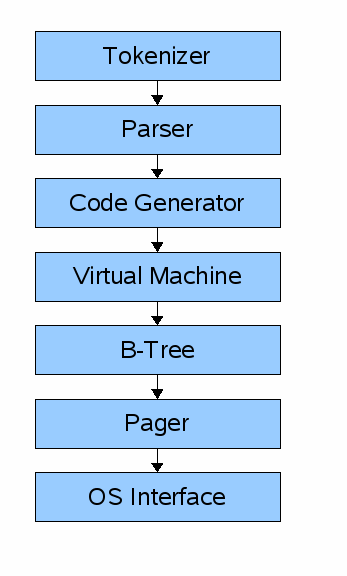
The above image shoes the parts of the application. It was so overwhelming on first look right. so, I have created a easy flow diagram to understand it. These are a basic parts of the SQLite architecture. Let we go over the each parts & its responsibilities.
Parser
A parser is a program that analyzes the user input, breaks it down into its constituent parts, and identifies the structure and meaning of the input.
Think of a parser as a linguistic expert who takes a sentence and identifies the individual words, their meanings, and how they relate to each other.
In database SQL query was a user input. The parser will parse & validate user query & validate it then generate a bytecode. If you want to dive deep into parser itself a another topic. Am not going to discuss that over here as it out of scope.
Tokenizer
The next step is tokenizing, which is the process of converting the tokens into a format that the code generator can execute. This is done by a tokenizer, which is a program that takes the tokens generated by the parser and converts them into a sequence of tokens/bytecode that can be executed.
Virtual Machine
The virtual machine takes bytecode generated by the front-end as instructions. It can then perform operations on one or more tables or indexes, each of which is stored in a data structure called a B-tree.
B-tree
A B-tree is a self-balancing search tree used to organize and store sorted data efficiently for quick access, insertion, and deletion.
Each B-tree consists of many nodes. Each node is one page in length. The B-tree can retrieve a page from disk or save it back to disk by issuing commands to the pager. I moving forward as you already have a solid understanding of B-tree data structure.
If would appreciate to watch the B-tree explanation.
Pager
The pager receives commands to read or write pages of data. It is responsible for reading/writing at appropriate offsets in the database file. It also keeps a cache of recently-accessed pages in memory, and determines when those pages need to be written back to disk.
OS Layer
The OS interface is the layer that differs depending on which operating system SQLite was compiled for. This is mostly related in which platform SQLite is going to be used.
Implementation
A journey of a thousand miles begins with a single step
let’s start with something a little more straightforward.
For a simple & explanation purpose we are going to build a SQLite clone database with a constrains. Our database is going to have only one table & going to hold columns of Id , username , email. We are going to implement only a insert & select statement.
Parser
As we discussed on above section parser is code which going to break the user inputs. Am not going to impalement a complete parser.
const COMMAND_SELECT: &str = "select";
const COMMAND_INSERT: &str = "insert";
const COMMAND_EXIT: &str = "exit";
fn main() {
print!("\n mini-sqlite>>");
io::stdout().flush().unwrap();
let mut buffer = String::new();
io::stdin().read_line(&mut buffer).unwrap();
let command = buffer.trim();
match command {
COMMAND_EXIT => {
println!("Exiting....");
exit(0);
}
_ => {}
}
match &command[..6] {
COMMAND_INSERT => {
println!("Insert statement....");
}
COMMAND_SELECT => {
println!("select statement....");
}
_ => println!("Invalid mini-sqlite command"),
}
}
}
Now you could see how simple is our parser. We are going to take first 6 parts of a string & comparing to commands we are going to support. The production database use a different parsing strategies. So, now we are ready with our basic parser.
Tokenizing we are going to skip & keep things straightforward for simplicity. In real world it have more details like operators & its operands. Example select * from companies where id = 12 . We need to parse the equal & then its value. Nested queries need to be tokenized so, we can have a right hierarchy.
Storage calculations
As we going to store a table with three columns id, username , email. We are going to calculate how much bytes need to store a single row of data. As we know all text / string columns in our database we need to specify our length of that column. Example : Varchar - 255 . This was really important to calculate the row size.
| column name | size in bits | size in bytes |
| id | 32 | 4 |
| username [ length - 16 ] | 128 | 16 |
| email [ length - 32 ] | 256 | 32 |
| Total | 52 |
Max length of username we are going to allow is 16 char long & for email its only 32 chars long. So we calculated a storage space we need to store a single row in a our database file. If we want to store 10 rows then multiply by in by 10 which is equal to 520 bytes.
Understanding Storage with Pages in Databases
When storing data in a database, it’s not saved as individual rows scattered across the disk. Instead, databases use a concept called pages to manage and optimize disk storage. A page is the smallest unit of data storage in a database and typically has a fixed size, such as 4 KB or 8 KB. Let’s see how this works and how the row size calculations play into it.
How Pages Work in Databases
Think of a page as a container that holds multiple rows of data. Rather than writing each row separately to the disk (which would be inefficient), databases batch rows together into pages before storing them. Pages are then written to and read from the disk as a whole, minimizing the number of disk operations, which are relatively slow compared to in-memory operations.
The Row-Page Relationship
From our earlier calculation, a single row in our example database requires 52 bytes. If we use a page size of 4 KB (4096 bytes), we can calculate the number of rows that can fit into a single page:
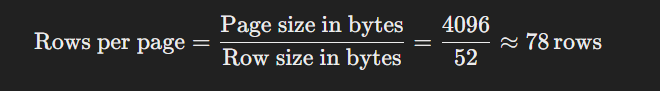
This means one page can store up to 78 rows of data. If we have more than 78 rows, the database will allocate additional pages to accommodate the data.
Pages and Disk I/O
When the database needs to read or write data, it doesn’t handle individual rows—it works with entire pages. For example:
Reading data: If you query a single row, the database fetches the entire page containing that row from disk into memory.
Writing data: If you update a row, the database modifies the page in memory and writes the updated page back to disk during a process called "flushing."
This page-based approach is crucial for efficiency because it reduces the number of expensive disk I/O operations. Instead of accessing the disk for each row, the database retrieves or writes data in larger chunks.
Fragmentation and Wasted Space
While the page concept is efficient, there’s one potential downside: wasted space.
If the rows don’t perfectly fill the page, the unused space in the page remains empty.
For example, if a page has 4096 bytes but only stores 78 rows (78 × 52 = 4056 bytes), there will be 40 bytes of unused space in the page.
Over time, this can lead to fragmentation, where small chunks of unused space accumulate, slightly reducing storage efficiency.
If you have more data than can fit into a single page, the database will allocate additional pages. For instance
Storing 1,000 rows requires approximately 1,000×52=52,0001,000 \times 52 = 52,0001,000×52=52,000 bytes.
With 4 KB pages, this would need 52,000/4,096≈1352,000 / 4,096
approx 1352,000/4,096≈13 pages to store the data.
I hope now it makes sense which we learned about anatomy of hard disk. Pages are a fundamental concept that bridges the gap between how databases manage data logically (rows and tables) and how data is stored physically (disk blocks).
Let’s code
1. Define Constants for Database Configuration
The code starts by defining several constants:
MAX_USERNAME_LENandMAX_EMAIL_LEN: Define the maximum lengths of theusernameandemailfields in characters.PAGE_SIZE: The size of a single page in bytes (4 KB in this case).TABLE_MAX_PAGES: The maximum number of pages the database can manage (2 pages here).DB_FILENAME: The name of the file where the database will be stored.
These constants allow for easy configuration of the database’s structure and storage.
const MAX_USERNAME_LEN: usize = 16;
const MAX_EMAIL_LEN: usize = 32;
const PAGE_SIZE: usize = 4096;
const TABLE_MAX_PAGES: usize = 2;
const DB_FILENAME: &str = "mini_sqlite.db";
2. Define the Row Structure
The Row struct represents a single row of data in the table.
Each row has:
id: A 32-bit unsigned integer.username: A fixed-size array of 16 bytes to store the username.email: A fixed-size array of 32 bytes to store the email.
Key Methods:
Row::new(id, username, email): Creates a new row by copying the provided values into fixed-size arrays.Row::serialized_size(): Returns the fixed size (52 bytes) of a serialized row, calculated as: Size of id (4 bytes)+Size of username (16 bytes)+Size of email (32 bytes)=52 bytes\text{Size of id (4 bytes)} + \text{Size of username (16 bytes)} + \text{Size of email (32 bytes)} = 52 \, \text{bytes}Size of id (4 bytes)+Size of username (16 bytes)+Size of email (32 bytes)=52bytes
#[derive(Serialize, Deserialize, Debug)]
struct Row {
id: u32,
username: [u8; MAX_USERNAME_LEN], // Fixed-size array for username
email: [u8; MAX_EMAIL_LEN], // Fixed-size array for email
}
impl Row {
fn new(id: u32, username: &str, email: &str) -> Self {
let mut username_bytes = [0; MAX_USERNAME_LEN];
username_bytes[..username.len()].copy_from_slice(username.as_bytes());
let mut email_bytes = [0; MAX_EMAIL_LEN];
email_bytes[..email.len()].copy_from_slice(email.as_bytes());
Row {
id,
username: username_bytes,
email: email_bytes,
}
}
fn serialized_size() -> usize {
return 52;
}
}
3. Define the Page Structure
The Page struct represents a single page in the database.
Each page has a
datafield, a fixed-size array of 4096 bytes.A page is initialized with zeros, representing empty space.
Pages are the building blocks for storing rows in memory and on disk.
struct Page {
data: [u8; PAGE_SIZE],
}
impl Page {
fn new() -> Self {
Page {
data: [0; PAGE_SIZE],
}
}
}
4. Create the PageManager
The PageManager manages multiple pages and handles row insertion, retrieval, and file persistence.
Key Methods:
PageManager::new(): Initializes the page manager with empty pages.PageManager::insert_row(row_data):Searches for a free slot in the pages where the row can fit.
If a free slot is found, the row is copied into the page.
Returns an error if all pages are full.
PageManager::flush_to_file():Writes all pages to a database file (
mini_sqlite.db).Ensures data persistence on disk.
PageManager::load_from_file():- Loads the contents of the database file into memory, restoring the state of the pages.
struct PageManager {
pages: [Page; TABLE_MAX_PAGES],
}
impl PageManager {
fn new() -> Self {
PageManager {
pages: core::array::from_fn(|_| Page::new()),
}
}
}
fn insert_row(&mut self, row_data: &[u8]) -> Result<(), String> {
for page in self.pages.iter_mut() {
let mut free_slot = 0;
while free_slot < PAGE_SIZE && page.data[free_slot] != 0 {
free_slot += Row::serialized_size(); // Skip existing rows
}
if free_slot < PAGE_SIZE {
page.data[free_slot..free_slot + Row::serialized_size()]
.copy_from_slice(row_data);
return Ok(());
}
}
Err(format!(
"Database full (maximum {} rows)",
TABLE_MAX_PAGES * (PAGE_SIZE / Row::serialized_size())
))
}
fn flush_to_file(&self) -> Result<(), std::io::Error> {
let mut file = OpenOptions::new()
.write(true)
.create(true)
.open(DB_FILENAME)?;
for page in &self.pages {
file.write_all(&page.data)?;
}
file.flush()?; // Ensure data is written to disk
Ok(())
}
fn load_from_file(&mut self) -> Result<(), std::io::Error> {
let mut file = OpenOptions::new().read(true).open(DB_FILENAME)?;
for page in self.pages.iter_mut() {
file.read_exact(&mut page.data)?;
}
Ok(())
}
5. Handle User Commands
The program operates in a loop, allowing users to enter commands. It supports the following commands:
Command: insert
Syntax:
insert <id> <username> <email>The command creates a
Rowwith the provided values.The
Rowis serialized using thebincodecrate into binary data.The serialized data is passed to
PageManager::insert_row(), which finds space for the row in a page.If the row is successfully inserted, the updated pages are flushed to the file.
Command: select
The command iterates through all pages and deserializes each row found.
For each row, the program prints the
id,username, andemailfields.Deserialization is handled by the
deserialize_row()function using thebincodecrate.
Command: exit
- Exits the program.
use bincode::{deserialize, serialize};
use serde::{Deserialize, Serialize};
use std::{
fs::{File, OpenOptions},
io::{self, Read, Seek, SeekFrom, Write},
process::exit,
};
const COMMAND_EXIT: &str = "exit";
const COMMAND_SELECT: &str = "select";
const COMMAND_INSERT: &str = "insert";
const MAX_USERNAME_LEN: usize = 16;
const MAX_EMAIL_LEN: usize = 32;
const PAGE_SIZE: usize = 4096;
const TABLE_MAX_PAGES: usize = 2;
const DB_FILENAME: &str = "mini_sqlite.db";
#[derive(Debug)]
struct Page {
data: [u8; PAGE_SIZE],
}
impl Page {
fn new() -> Self {
Page {
data: [0; PAGE_SIZE],
}
}
}
#[derive(Debug)]
struct PageManager {
pages: [Page; TABLE_MAX_PAGES],
}
impl PageManager {
fn new() -> Self {
// Correct return type: Self
PageManager {
pages: core::array::from_fn(|_| Page {
data: [0; PAGE_SIZE],
}),
}
}
fn insert_row(&mut self, row_data: &[u8]) -> Result<(), String> {
// Find a free slot in any page
for page in self.pages.iter_mut() {
let mut free_slot = 0;
while free_slot < PAGE_SIZE && page.data[free_slot] != 0 {
free_slot += Row::serialized_size(); // Skip existing rows
}
if free_slot < PAGE_SIZE {
// Found a free slot, deserialize and insert
page.data[free_slot..free_slot + Row::serialized_size()].copy_from_slice(row_data);
return Ok(());
}
}
Err(format!(
"Database full (maximum {} rows)",
TABLE_MAX_PAGES * (PAGE_SIZE / Row::serialized_size())
))
}
fn flush_to_file(&self) -> Result<(), std::io::Error> {
let mut file = OpenOptions::new()
.write(true)
.create(true)
.open(DB_FILENAME)?;
for page in &self.pages {
file.write_all(&page.data)?;
}
file.flush()?; // Ensure data is written to disk
Ok(())
}
fn load_from_file(&mut self) -> Result<(), std::io::Error> {
let mut file = OpenOptions::new().read(true).open(DB_FILENAME)?;
for page in self.pages.iter_mut() {
file.read_exact(&mut page.data)?;
}
Ok(())
}
}
#[derive(Serialize, Deserialize, Debug)]
struct Row {
id: u32,
username: [u8; MAX_USERNAME_LEN], // Fixed-size array for username
email: [u8; MAX_EMAIL_LEN], // Fixed-size array for email
}
impl Row {
fn new(id: u32, username: &str, email: &str) -> Self {
let mut username_bytes = [0; MAX_USERNAME_LEN];
username_bytes[..username.len()].copy_from_slice(username.as_bytes());
let mut email_bytes = [0; MAX_EMAIL_LEN];
email_bytes[..email.len()].copy_from_slice(email.as_bytes());
Row {
id,
username: username_bytes,
email: email_bytes,
}
}
fn serialized_size() -> usize {
return 52;
}
}
fn main() {
let mut page_manager: PageManager = PageManager::new();
// Try loading data from file
if let Err(e) = page_manager.load_from_file() {
if e.kind() != std::io::ErrorKind::NotFound {
eprintln!("Error loading database: {}", e);
return;
}
println!("No database file found, creating a new one.");
} else {
println!("Database loaded from file.");
}
loop {
print_prompt();
let mut buffer = String::new();
io::stdin().read_line(&mut buffer).unwrap();
let command = buffer.trim();
match command {
COMMAND_EXIT => {
println!("Exiting....");
exit(0);
}
_ => {}
}
match &command[..6] {
COMMAND_EXIT => {
println!("Exiting....");
exit(0);
}
COMMAND_INSERT => {
let words: Vec<&str> = command.split_whitespace().collect();
let mut id = 0;
match words[1].parse::<u32>() {
Ok(num) => id = num,
Err(e) => println!("Error parsing string: {}", e),
}
let row = Row::new(id, words[2], words[3]);
let encoded: Vec<u8> = bincode::serialize(&row).unwrap();
if let Err(err) = page_manager.insert_row(&encoded) {
println!("Error inserting data: {}", err);
} else {
println!("Row inserted successfully!");
page_manager.flush_to_file();
}
}
COMMAND_SELECT => {
let mut row_offset = 0;
let mut row = 1;
let mut page: usize = 0;
loop {
match page_manager.pages.get(page) {
Some(value) => {}
None => exit(0),
}
if page_manager.pages[page].data[row_offset] != 0 {
let row_data = &page_manager.pages[0].data
[row_offset..row_offset + Row::serialized_size()];
if let Ok(row) = deserialize_row(row_data) {
println!(
"{:?} {:?} {:?}",
&row.id,
String::from_utf8_lossy(&row.username)
.trim_matches('\0')
.to_string(),
String::from_utf8_lossy(&row.email)
.trim_matches('\0')
.to_string(),
);
}
row_offset = Row::serialized_size() * row;
row += 1;
} else {
break;
}
}
}
_ => println!("Invalid mini-sqlite command"),
}
}
}
fn print_prompt() {
print!("\n mini-sqlite>>");
io::stdout().flush().unwrap();
}
fn deserialize_row(data: &[u8]) -> Result<Row, bincode::Error> {
bincode::deserialize(data)
}
6. Row Serialization and Deserialization
Serialization: Converts a
Rowinto a binary format for efficient storage. This is done using thebincode::serialize()function.Deserialization: Converts the binary data back into a
Rowstructure. This is handled by thebincode::deserialize()function.
Why serialization & deserialization?
Persistent Storage:
- In-memory data structures exist only as long as the program is running. To make the data persistent across program restarts, it needs to be stored in a file or database in a format that can be saved to disk.
Convert to a File-Compatible Format:
- Data in memory is stored as pointers, references, and dynamically allocated structures, which are meaningless outside the program. Serialization converts these structures into a format (e.g., JSON, binary, BSON) that can be written to a file.
Platform Independence:
- Serialized data can be stored in a platform-independent format, making it accessible on different architectures or programming languages.
Efficiency:
- A compact binary serialization format can save space and improve the speed of reading and writing data to disk compared to plain-text formats.
7. How Rows Are Stored in Pages
- Each page can hold multiple rows, as calculated earlier:
When a row is inserted, the program looks for the first available free slot in the pages.
Rows are written contiguously in the page’s
dataarray.
8. Persistence to Disk
The database uses a file (
mini_sqlite.db) to persist data across sessions.When data is flushed:
- All pages are written sequentially to the file.
When data is loaded:
- The file contents are read back into memory, restoring the state of the pages.
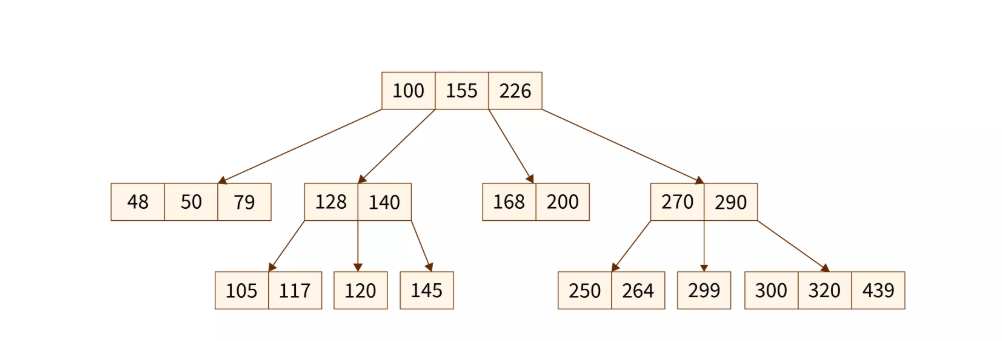
Why Real Databases Use B-Trees
Real-world databases prioritize scalability, ordering, and efficient disk usage. Here’s why B-trees are the go-to data structure:
Efficient Disk Usage:
Disks (and SSDs) read and write in blocks (e.g., 4KB).
B-trees are designed to align with these blocks, ensuring minimal disk I/O by grouping keys and pointers into nodes that fit into one block.
Ordered Data:
B-trees keep keys sorted, enabling efficient range queries and ordered traversals.
For example, finding all users with IDs between
100and200is straightforward.
Scalability:
B-trees grow dynamically with the data.
Unlike hashmaps, they don’t need expensive resizing when the data grows; they rebalance themselves by splitting or merging nodes.
Balanced Structure:
- The tree remains balanced, ensuring O(log N) time complexity for lookups, insertions, and deletions.
Let test Our database
Start the program:
mini-sqlite>>Insert a row:
mini-sqlite>> insert 1 john_doe john@example.com Row inserted successfully!Insert another row:
mini-sqlite>> insert 2 jane_doe jane@example.com Row inserted successfully!Select rows:
mini-sqlite>> select 1 john_doe john@example.com 2 jane_doe jane@example.comExit the program:
shellCopyEditmini-sqlite>> exit Exiting...
I hope now its clear how complex as this program illustrates key database concepts, such as page-based storage, serialization, and persistence, while providing a hands-on example of a mini SQLite-like database implementation.
Beyond the Basics
What we’ve explored in this article is just the tip of the iceberg. While our mini database implementation demonstrates fundamental concepts like row storage, page management, and basic file I/O, real-world databases are far more complex and powerful. Let’s briefly touch on some of the advanced features and mechanisms that make modern databases efficient, reliable, and capable of handling massive workloads.
1. ACID Properties
Real-world databases ensure Atomicity, Consistency, Isolation, and Durability (ACID) to guarantee data integrity. Here's a quick overview:
Atomicity: Ensures all parts of a transaction are completed or none at all. If a failure occurs mid-transaction, the database rolls back to its previous state.
Consistency: Guarantees that a transaction brings the database from one valid state to another, maintaining all rules, constraints, and relationships.
Isolation: Multiple transactions can execute concurrently without interfering with each other, maintaining the illusion that each transaction is executed sequentially.
Durability: Once a transaction is committed, the changes are permanent—even in the event of a crash or power failure.
Our mini database lacks transaction handling, but real-world systems achieve atomicity and durability through write-ahead logs (WAL) and transaction logs, which record changes before they are applied to the database.
2. Recovery Mechanisms
In production systems, databases must recover gracefully from failures, whether due to hardware malfunctions, power outages, or software crashes. Advanced recovery mechanisms include:
Crash Recovery: Restoring the database to a consistent state using transaction logs or snapshots.
Checkpoints: Periodically saving the database state to reduce recovery time in case of failure.
Redo and Undo Logs: Ensuring committed transactions are applied (redo) and uncommitted changes are rolled back (undo).
3. Concurrency Control
Our implementation handles only a single operation at a time, but real-world databases are built to handle thousands of simultaneous queries and updates. This is achieved using techniques like:
Locks: Preventing conflicting operations on the same data (e.g., read vs. write conflicts).
Optimistic Concurrency Control: Allowing multiple transactions to proceed and resolving conflicts at commit time.
Multiversion Concurrency Control (MVCC): Maintaining multiple versions of data to allow readers and writers to operate without blocking each other.
4. Query Optimization
In our mini database, there is no concept of query optimization. In contrast, modern databases include sophisticated query planners that analyze and optimize SQL queries to determine the most efficient way to retrieve or update data. Techniques include:
Indexing: Creating specialized data structures like B-trees to speed up lookups.
Cost-based Optimization: Evaluating multiple query execution plans and selecting the one with the lowest cost.
5. Distributed Databases
Many modern databases operate in a distributed environment, where data is spread across multiple servers or even data centers. This enables:
High Availability: Redundancy ensures the database remains operational even if some nodes fail.
Horizontal Scaling: Adding more nodes to handle increased workloads.
Consistency Models: Balancing trade-offs between strict consistency, availability, and partition tolerance (as per the CAP theorem).
Conclusion
Building a database from scratch is a fascinating journey that exposes the complexities hidden beneath the surface of everyday applications. While our implementation demonstrates the foundational concepts, modern databases operate at an entirely different scale, integrating advanced techniques like ACID compliance, recovery mechanisms, concurrency control, and query optimization.
This complexity underscores the incredible amount of engineering that goes into making databases reliable and efficient. For those eager to dive deeper, exploring these advanced topics offers valuable insights into the core of modern computing. Whether you’re curious about how SQL engines optimize queries or how distributed databases ensure fault tolerance, the world of databases is full of challenges and opportunities waiting to be explored.
The code for this project is open-source and available on GitHub. Feel free to explore. Your feedback and suggestions are always welcome!
📂 GitHub Repository: Mini SQLite in Rust
Happy coding, and welcome to the fascinating world of databases! 🚀




