Shard Database to handle a million records
Sharding is a type of database partitioning that separates large databases into smaller & easily managed parts.These smaller parts are called shards.

4+ years of experience building scalable backend systems using Node.js, Laravel, and Go. Moving towards Solution Architecture with strong foundations in distributed systems and cloud.
Passionate about system design, databases, protocols, and high-performance services.
Laravel Stream-Pulse Laravel package for Event-Driven Architecture (EDA) using Redis Streams.
Enables scalable event publishing & consuming directly inside Laravel. Ideal for real-time apps and microservice event workflows. GoQueue Lightweight, production-ready job queue in Go with multiple backends (Redis, SQLite, SQS).
Supports retries, dead-letter queues, and graceful shutdown. Benchmarked for high-throughput event processing.
Introduction
Hi, folks. In today's data-driven world, where the volume and velocity of information continue to grow exponentially, To design a database handling a million rows. There are multiple ways to handle it. In this article, we are going to explore the technique called Sharding with a practical explanation.
What is Shard?
The word “Shard” means “a small part of a whole“. Hence Sharding means dividing a larger part into smaller parts. That means dividing the database into small databases.
Types of Sharding
There are different types of sharding. In this article, we are going to see major two types.
Horizontal Sharding
Vertical Sharding
Vertical Sharding
Vertical sharding involves splitting data based on specific columns or attributes rather than a range. In this approach, different shards hold different sets of columns for a given dataset. For instance, one shard may contain customer names and contact information, while another shard holds customer purchase history. Vertical sharding can be useful when certain attributes are accessed more frequently than others or when different attributes require different levels of resources.
Horizontal Sharding
Horizontal sharding involves distributing data across multiple databases or servers based on a range of values. In this approach, each shard contains a subset of data that falls within a specific range.
For example:
Data could be partitioned based on customer IDs, where one shard contains customer data with IDs from 1 to 100,000, and another shard contains IDs from 100,001 to 200,000.
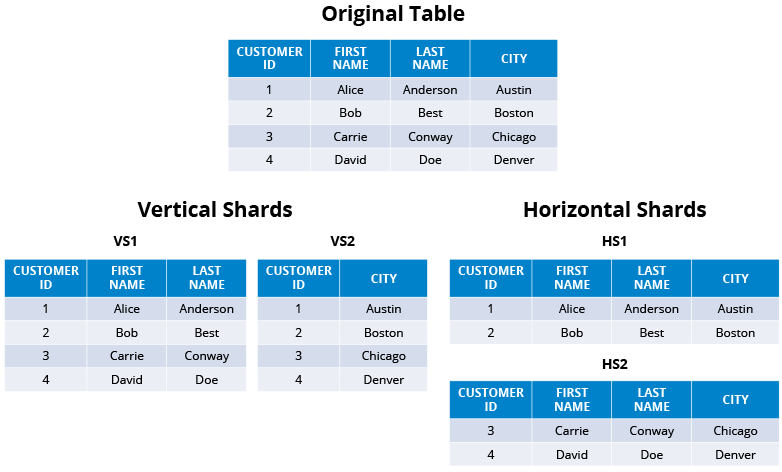
I hope you have a clear idea about what is sharding now. To implement it in your system. we need to know some more techniques & Jargon. Let's dive into it.
Consistent Hashing
Consistent Hashing is a specific type of algorithm to achieve data sharding.
Consistent Hashing is a distributed hashing scheme that operates independently of the number of servers or objects in a distributed hash table.

In Layman Terms
Let me explain the basic idea behind consistent hashing for a more in-depth explanation check out the article Understanding and implementing consistent hashing.
We know that the hashing function converts the plain text into some random set of characters with a defined length. So, consider that we have 3 instances of databases running on different ports 5432, 5433, & 5434.
Now we have 3 different databases as you understood Horizontal Sharding. We need to find which instance of database we have to read & write. To solve this we are going to apply are knowledge of the hash function.
| PORT NO | HASH |
| 5432 | NTQzMg== |
| 5433 | NTQzMw== |
| 5434 | NTQzNA== |
As we know hashing the port numbers will give the same hash every time. When every we decode that hash we get back the port number. So, now we can know on which database instance we have to do our read & write operations.
It's not a working explanation. I have oversimplified for understanding it. I hope now you got a complete idea about it.
Methods of database sharding?
Range-based sharding
Hash-Based Sharding
Directory sharding
Geo sharding
You can apply different methods of sharding as per the use case. However, sharding is one among several other database scaling strategies. Explore some other techniques. Implementation & explanation of each method is beyond the scope of this article.
Pros of Sharding
Improve response time
Data retrieval takes longer on a single large database. The database management system needs to search through many rows to retrieve the correct data. By contrast, data shards have fewer rows than the entire database. Therefore, it takes less time to retrieve specific information or run a query, from a shared database.
Scale efficiently
A growing database consumes more computing resources and eventually reaches storage capacity. Organizations can use database sharding to add more computing resources to support database scaling. They can add new shards at runtime without shutting down the application for maintenance.
Improves Reliability
Lots of shards mitigate problems that affect individual instances. With one huge DB, an outage takes the whole site down. With 100 shards, a single-instance outage affects only 1% of your data world.
Cons of Sharding
Shards can be complicated to get right, particularly if your shard key isn’t obvious.
You occasionally have to worry about splitting shards, or very occasionally about merging shards. This can be quite complicated.
Applications need to be aware of the details of database organization, at least at some level. Joins across shards are not easily doable. If you need to do cross-shard joining, you probably need a data warehouse or some type of alternate reporting data world.
No Native Support Sharding is not natively supported by every database engine.
Conclusion
Sharding is a great solution when the single database of your application is not capable to handle & store a huge amount of growing data. Sharding helps to scale the database and improve the performance of the application. However, it also adds some complexity to your system.
I hope you got valuable information today. For more content like this like & share in your communities.




